На самом деле OpenAI не играет в доту. Нам нечему у него учиться
Победа для бота – не цель, а результат случайностей.
Во время недавней AMA-сессии на реддите создатели OpenAI рассказали, что со следующей недели закроют соревновательную часть проекта. По их словам, после победы OpenAI над OG с 17 героями в пуле они извлекли из этого направления все, что хотели. Переживать нет причин – став прорывом в техническом плане, боты так и не стали прорывом в игровом. Если искусственный интеллект для го победил человека и изменил многовековое представление об игре, то у OpenAI этого не вышло.
Боты понимают суть доты?
Нет. У них отсутствует абстрактное мышление. Компьютер воспринимает только четкую цель, не строит стратегии в нашем понимании и не ищет креативный подход. Главная цель доты – сломать трон соперника, но прийти к ней напрямую невозможно – придется выполнять множество промежуточных задач. Из-за этого и возникают все их проблемы.
В шахматах и го партию можно записать как последовательность ходов. Шахматный суперкомпьютер Deep Blue, который победил Каспарова, знал и просчитывал все возможные победные комбинации. Искусственный интеллект для го AlphaGO изучал матчи профессионалов и проводил игры внутри себя. В случае, если они допускали ошибки и проигрывали, они возвращались назад и искали комбинацию, которая привела к поражению. И Deep Blue, и AlphaGo изначально представляли концепцию, которой нужно придерживаться всю игру. Но киберспорт – не тот случай.
Дота – не тот случай. В ней слишком много случайностей и практически нет аксиом – все, что мы знаем о ней, верно до определенного момента.
Убивать крипов – хорошо? Отлично, попробуйте заняться этим в драке пять на пять. Выходить на врага и отдаваться ему – плохо? Но что, если соперник идет на вашу базу, а смерть – единственный способ отвлечь его и выиграть время? Это интуитивные моменты, которые нельзя передать боту.

Как ботов научили побеждать?
Изначально искусственный интеллект ошибочно ассоциировали с программированием. Но это неверно по двум причинам:
- он требует слишком много параметров. Например, у того же OpenAI их 167 миллионов. Просто представьте, сколько времени ушло бы у группы разработчиков на создание такого массива данных;
- рано или поздно подобные усилия окажутся бесполезны – бот встретится с ситуацией, которая не была запрограммирована.
Для того, чтобы избежать этих проблем, при создании искусственного интеллекта используется обучение с подкреплением (Reinforcement Learning). Суть: агент попадает в среду, с которой взаимодействует самостоятельно, чтобы понять правильные схемы поведения. OpenAI находился в такой среде 180 лет каждый день с июня прошлого года.
Тут все о первом матче ботов против команды бывших про
Но здесь возникают новые трудности – из-за удаленности цели (Long horizon) бот не сможет оценить плюсов или минусов конкретных действий. Выполнив достаточно промежуточных задач, он победит случайно, не планируя это со старта игры, и закрепит любую последовательность действий победного матча как верную. Пришел на линию, зашел в лес, постоял у кэмпа, убил крипов, съел два манго, убил слабых ботов и снес им базу? Повторить, пока эту последовательность не победит другая.
Такой ИИ похож на ребенка-маугли, который пытается заговорить – может, он это и сделает, но кто оценит правильность слов? Даже с безграничным временем тренировок вывод правильного алгоритма затянулся бы на годы. И, чтобы натолкнуть ботов на правильный путь, им дали награды.
Представьте ослика, который идет вперед, когда перед его носом удочка с морковью. Так и с нашим ИИ: чтобы он победил, разработчики придумали поощрение за правильные действия и штрафы за неправильные.
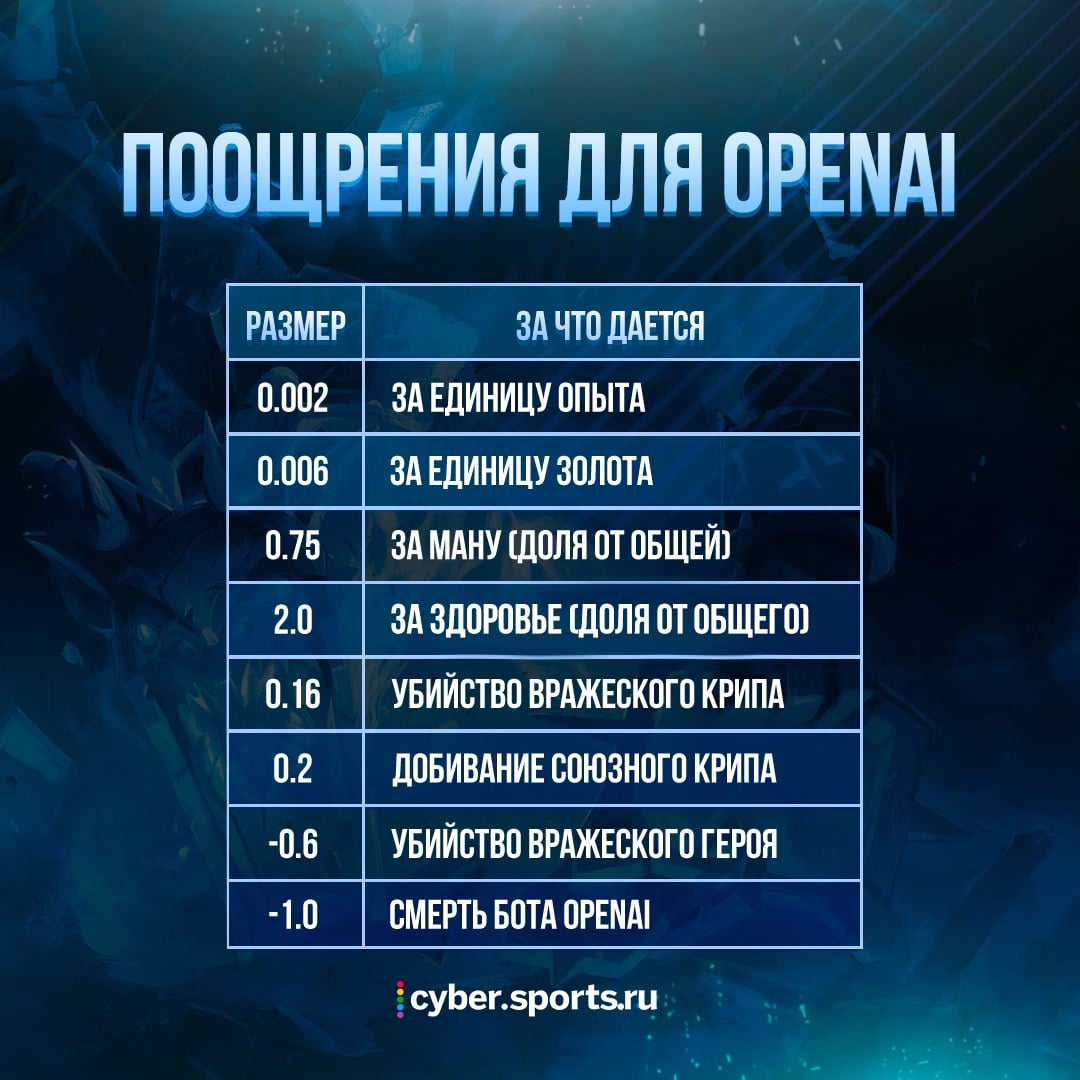
Понятие правильного и неправильного действия очень условны. К примеру, у убийства отрицательный рейтинг – ведь убийства дают золото и опыт (у которых рейтинг положительный); в итоге фраг все равно расценивается как награда, а в противном случае боты излишне гонялись бы за убийствами. Но некоторым действиям назначить награду невозможно – например, как оценивать поставленный вард? Или подобранную руну?
А теперь время сделать паузу и расслабиться за видео с милой вороной. Здесь она выполняет сложное, многоступенчатое задание, чтобы получить еду. Но ворона не продумала ход действий изначально. Она уже умела делать отдельные элементы задания и, оказавшись в замешательстве, решила выполнять действия, которые ранее приносили ей награду.
Ничего не напоминает? OpenAI – это та же ворона, только последовательность его действий гораздо длиннее. Но суть остается прежней – в начале игры у ИИ нет логической цели сломать трон, он выполняет микрозадачи за микронаграды. И уже они приводят к победе.
Боты учатся на своих ошибках?
И да, и нет. В выполнении мелких заданий, которые приводят к награде, они бесконечно тренируются и достигают совершенства. Но некоторым действиям невозможно назначить награду. Например, как оценивать поставленный вард? Без адекватного поощрения боты так и не научились вардить, и в итоге мы, спустя почти год разработки, видим вот такие варды:

Среди других элементов, которым боты так и не научились – смоки, игра против инвиза, защита Рошана. Все эти моменты требуют интуиции и абстрактного мышления, чему OpenAI в текущем виде не может научиться.
Их постоянные байбэки – тоже плохо?
Относительно. Со стороны ранний выкуп выглядит интересно – герой теряет мало золота в обмен на возможность пушить, фармить и получать новое золото и опыт. Но причина, по которой бот байбэкается, не такая глубокая и философская – его поощряют за золото и не штрафуют за его потерю, а значит выкуп – отличный способ держать темп и заслужить новую награду. OpenAI не открыл доту заново – это ворона решила ребус, чтобы получить еще еды.
А что с равномерным распределением золота?
Все зависит от ситуации. Позволить саппорту забрать крипа, чтобы он купил сапог и загангал мид – важно. Отдавать фарм Дизраптору, чтобы он купил аганим и выиграл вам игру – разумно. Жертвовать нетворсом Антимага, чтобы держать сохранить равновесие между всей командой – отличный выбор, если вы планируете закинуть матч.
Боты не видят различий. Они действуют ради поощрений – для них нет разницы, кто получит награду за золото или штраф за смерть. Более того, OpenAI не знает, как он победит в игре – он прогнозирует только ближайшие восемь минут игры и не видит долгосрочных перспектив. Если в лейте его убьет шестислотовая Спектра, он даже не поймет, в какой момент что-то пошло не так.
***
Все это приводит нас к довольно прозаичному выводу. OpenAI – огромный прорыв в искусственном интеллекте и методике обучения с подкреплением. Но с киберспортом его достижения не имеют ничего общего. Бот играет не в доту, он лучше всех решает задачу с камушками и палочками. Искусственный интеллект – не угроза человечеству, а механическая ворона с идеально отточенными рефлексами среди живых людей, которые играют в совсем другую игру.
Мы вдохновлялись текстом Эвана Пу – студента массачусетского университета технологий, который глубоко изучает искусственный интеллект. Ознакомиться с его материалом можно здесь.